Summary
I was searching for a Valorant API to collect and analyse some of my own match data. However the developers are not providing personal API keys for this particular game.
There are some websites which are publishing the Valorant data into the public domain. I decided to scrape my own match data which is being hosted on their web clients.
Though the volume of data highlighted on the website is limited compared to the actual volume of games I’ve played. I was only able to pull 30 matches worth of data.
However, it was worth learning about the overall web-scraping process and adding more capabilities to my toolkit.
Link to the project here: Valorant Web Scrapping Project
Scrapy - Web Scraper
I used a python library called scrapy as my web-crawling tool and the website being interrogated was https://dak.gg/valorant/en/profile/FilPill-EUW
Initialising Scrapy Project
The command below creates all the starting files for building the web-crawler:
scrapy startproject val_scraper
Checking for 200 Response on Target Website
I initialised a scrapy shell with the command:
scrapy shell
Inside the shell, I make a request to the website to check that my scraper has permissions to scrape the website.
fetch ('https://dak.gg/valorant/en/profile/FilPill-EUW](https://dak.gg/valorant/en/profile/FilPill-EUW)a')
A successful connection will return a 200 response, otherwise any 4xx reponse code will inidicate an error or a lack of permissions to perform this specific operation.
Identifying Target For Scraping
My initial approach involved attempting to parse out the HTML classes within the div’s however it did not work successfully. Despite the data being kept inside the HTML tags,I could not access them with my scraper.
When I simulated the webscraper opening the website, it did not return any data at all. Just an empty HTML page with no data. Soonafter, I realised that javascript is being employed to dynamically load the data into the front-end.
Realising this occurrence, I changed my approach. On the inspect elements page, I naviagted to the XHR/Fetch network tab to view what kind of requests were being made to the website, I found an https request which returns my match data in JSON format.
The spider script shown below is what is being ustilised to scrape the match data from the page:
import scrapy
import json
class PlayerState(scrapy.Spider):
name = 'playerState'
start_urls = ['https://dak.gg/valorant/en/profile/FilPill-EUW']
headers = {
"accept":" application/json, text/plain, */*"
}
def parse(self, response):
url = 'https://val.dakgg.io/api/v1/accounts/JPnyLxsiavseiYbL8xtmWSuFRHdupX43u_hVynD5YScr2_Y32Wt2v5K-NvxvfDRWTL67AHdVSmoLTg/matches'
request = scrapy.Request(url,
callback = self.parse_api,
headers=self.headers)
yield request
def parse_api(self,response):
raw_data = response.body
data = json.loads(raw_data)
yield {
'matches':data['matches']
}
Running the spider
To run the spider you run the following command:
scrapy crawl playerState -O playerState.json
The playerState argument in the command is referring to the class defined in my spider.
The results are saved in a json file of my choosing.
Data Analysis
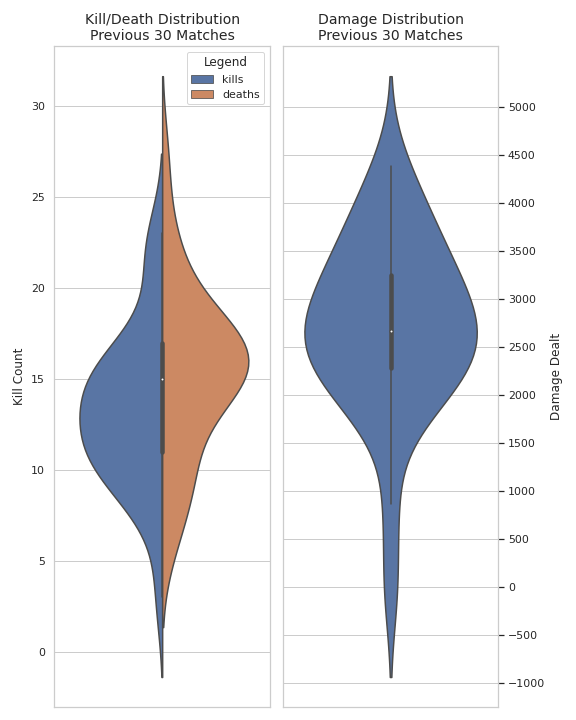
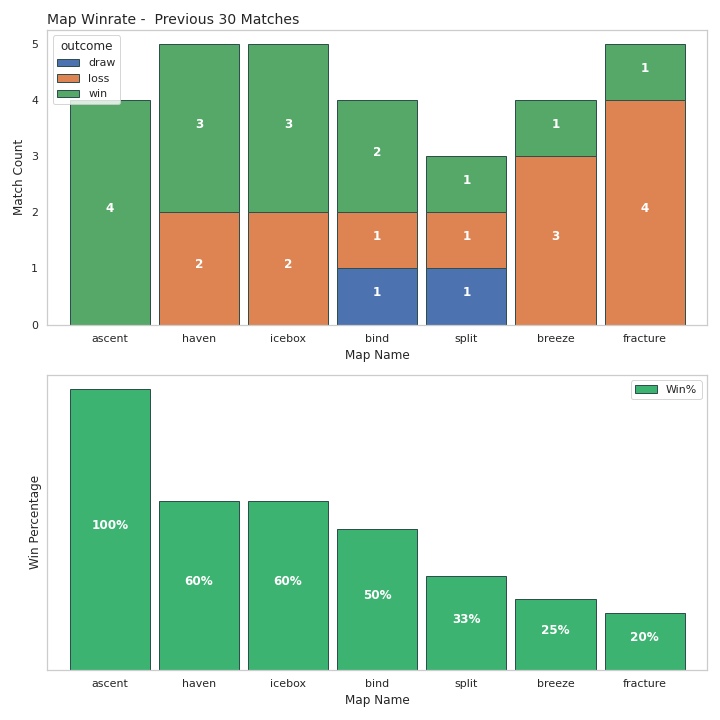
Since we are only pulling out 30 matches, we are fairly limited in generating valuable data visualisations.
However the goal was mainly to gain an understanding of the overall webscraping process.
These are some of the visualisations made using python: